Issue #173 - Multilingual Concept-To-Text NLG


Generalising Multilingual Concept-to-Text with Language Agnostic Delexicalisation
In the field of Natural Language Generation (NLG), Concept-To-Text is a task whereby an abstract meaning representation should be accurately rendered in natural language text. In today’s blog we look at work by Zhou et al, 2021 which explores generalisation of unseen inputs in a multilingual setting, where identifying the values for delexicalisation and subsequently generating the output text in a different language is more complicated.
In a nutshell
In order to generalise and handle unseen input, the NLG model generally delexicalises the input. This is done in a preprocessing step where occurrences of the Meaning Representation (MR) values in the text are replaced by placeholders, to give a level of abstraction to the model in training. During relexicalisation, a postprocessing step replaces the placeholders with values again. The process is hampered if the values are not correctly identified during delexicalisation, more so in a multilingual setting and particularly if the target language is morphologically rich, and therefore the values may be inflected. For illustration, see the lefthand diagram below, where there is an input MR and target delexicalisations in English and Russian. The double underlining indicates items missed by the delexicalisation process.

Similarly, sometimes items can be missed at relexicalisation where the morphology of the value is impacted by context. In the righthand diagram above we can see the double underlined items indicating where the model failed to account for context.
Novel contributions
In order to address these issues, Zhou et al (2021) propose:
- Language Agnostic Delexicalisation (LAD), a new delexicalisation method which leads to improved capturing, as can be seen in the illustration in lower part of first diagram
- Automatic Value Post Editing (VAPE), a character level post editing model for relexicalisation, which adapts to context as illustrated in lower part of second diagram
The novelty of Language Agnostic Delexicalisation (LAD) lies in the fact that it uses pretrained multilingual embeddings to match the input values to semantically similar n-grams, instead of simply lexically similar ones: for a given MR and text all possible mappings are determined and selected in a greedy fashion based on cosine similarity. The multilingual generation model is trained on delexicalised training data, and is extended with a language token to signal to the model which language to generate during inference.
Automatic Value Post Editing (VAPE) integrates a character-level post editing model which modifies the values that replace the placeholders during relexicalisation, adapting them to context. For example, a value may need to be pluralised or inflected, in the case of morphologically rich target languages. The VAPE consists of a character-level sequence-to-sequence model which takes as input the MR placeholder, the original value and the NLG output in which it is to be inserted. It then modifies the contextualised value to its correct form. It is trained on the data generated during delexicalisation: the pairs of MR values and matching n-grams, providing these differ.
LAD uses numbered generic placeholders (e.g., “X1”), and at relexicalisation needs to be able determine which input value replaces which placeholder. This is done by ordering model’s input based on the graph derived from its RDF triples: the process traverses all the nodes in a breadth-first-search, in the hope that the model will learn the input order for generating and relexicalising the placeholders.
Experiments
The experiments cover 5 languages in total and use the following datasets:
- 2017 and 2020 WebNLG challenges, which consist of sets of RDF triple pairs from 15 categories
- MultiWOZ and CrossWOZ datasets of dialogue acts and corresponding utterances (in English and Chinese respectively).
Input to all models is a simple linearisation of the MRs.
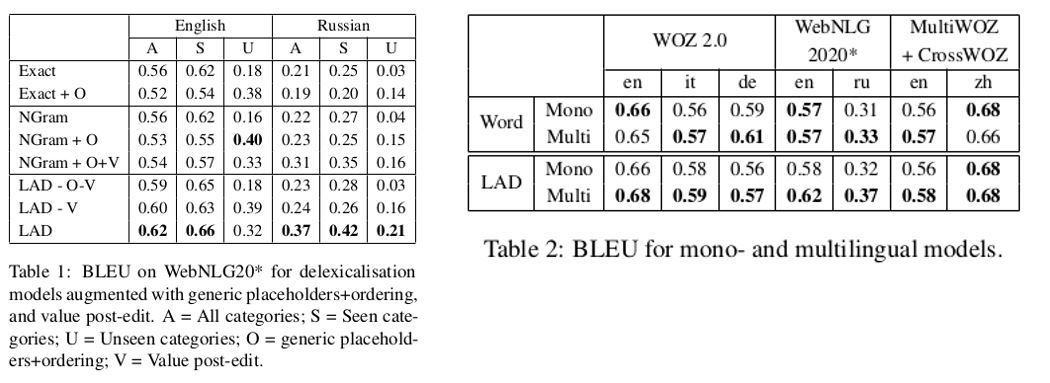
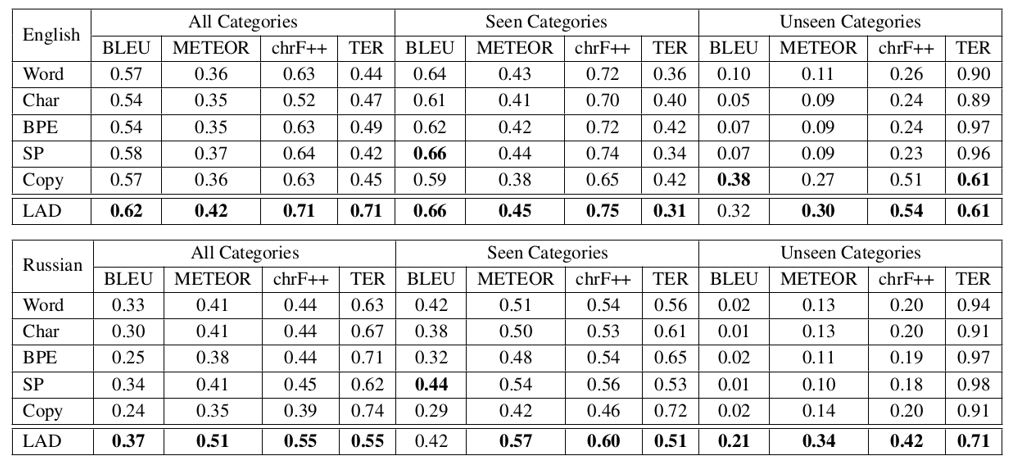
The ablation results in Table 1 illustrate how the different components of LAD (ordering and VAPE) contribute to overall performance. They also show how adding these components affects delexicalisation scores for previous delexicalisation strategies, Exact and NGram. In general, both ordering and VAPE help, particularly for morphologically rich and low resource languages. Looking at Table 2 we can see that the multilingual models outperform the monolingual ones, particularly for LAD. The Word model is the same as LAD but has no delexicalisation (therefore no VAPE or ordering either). For Word the monolingual model is better for English, due to the availability of data.
The full results for multilingual generalisation on the WebNLG20 are displayed in the table below. Here results are shown for various segmentation strategies. The Char, BPE and SP are variations that use characters, Byte-Pair-Encoding and SentencePiece. They found that BPE and Char underperform in delexicalisation, as they don’t cope with long dependencies between segmented words and may generate non-existing words. SP performs well for "Seen" category but fails to generalise on unseen data. Copy is a copy mechanism, which performs well for English but poorly for Russian where it fails to adapt. Overall, LAD outperforms all other models, and does particularly well at generalising to unseen data.
Conclusion
Zhou et al, 2021 introduce two new strategies for improving the multilingual concept-to-text task, Language Agnostic Delexicalisation (LAD) and Automatic Value Post Editing (VAPE). LAD maps the MR values using pretrained embeddings to match on semantic similarity instead of a simple lexical match. VAPE improves the form of the value when relexicalised, adapting it to context. Combined, the multilingual outperforms monolingual and outperforms previous models, particularly for morphologically rich languages.