Issue #179 - Charformer: Fast Character Transformers via Gradient-based Subwords


Introduction
In standard neural machine translation (MT) technology, words are split into subwords, based only on their frequency. This causes modelling issues for rare words. Additionally, in multilingual models, words in low-resourced languages are split into many subwords, which hurts performance on those languages and impacts cross-lingual transfer. In today's post, we take a look at the Charformer model, proposed by Tay et al. (2022), in which subword tokenization is learned as a gradient-based, end-to-end task. This method allows the subword segmentation algorithm to take lexical or semantic similarity into account.
Gradient-based Subword Tokenization
The first step consists of enumerating the possible subword blocks of different sizes, up to a maximum size. Thus, the input sequence is segmented into subword blocks of size 1 character, then in subword blocks of size 2 characters, etc. As a result, at each character position, there will be subword blocks of different sizes. A block scoring network is introduced to allow the model to learn which block to select for every character position. The block scoring network simply produces a score for each candidate block by using a softmax function. This is illustrated in the following figure, which shows the softmax weight at each character position for the input sequence “on subword tokenization,” for block sizes from 1 to 4.
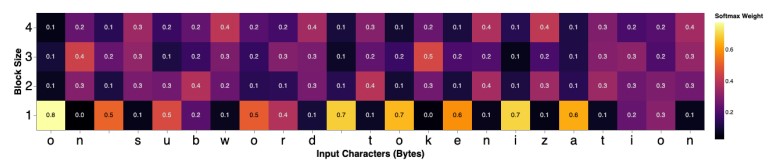 These weights have been learned with a multilingual Charformer (see the experiments section). The figure shows that this model learned to allocate single character subword blocks mainly to vowels and whitespaces. In addition, the model allocated larger blocks to the beginning and end consonants of a word.
These weights have been learned with a multilingual Charformer (see the experiments section). The figure shows that this model learned to allocate single character subword blocks mainly to vowels and whitespaces. In addition, the model allocated larger blocks to the beginning and end consonants of a word.
A latent subword representation is formed from these weights by summing the representations of all subword blocks at each position multiplied by their probability. Thus, the model learns an ideal subword block for each position. However, in contrast to deterministic subword tokenization algorithms, this selection is not a hard decision. Different possible segmentations can be considered at each position.
After learning a candidate block or mixture of blocks for each position, a downsampling function is used to reduce its sequence length by a fixed factor. This removes redundancies caused by adjacent positions selecting similar blocks.
Finally, the Charformer model is otherwise the same as a Transformer encoder-decoder model but taking as input the downsampled latent subwords instead of the standard subword embeddings. Note that it is faster than fully character-based models because it is based on (latent-)subword sequences instead of much longer character sequences. However, due to downsampling, it is also faster to train than standard subword-based models.
The model is pre-trained by masking N contiguous characters and trained to predict them in a sequence-to-sequence architecture.
Experiments
The method is evaluated on tasks of the GLUE test framework, namely sentiment classification, natural language inference, paraphrase detection and sentence similarity. Charformer is compared against state-of-the-art subword and character-based models. Overall, Charformer outperforms other character-level baselines trained under the same conditions, with the same number of parameters, while being much faster. Furthermore, Charformer is the only character-level model that performs on par or outperforms the standard subword-based models on some tasks in standard English.
In addition, as with other character-level models, Charformer performs particularly well on noisy data that contains spelling variations, typos, and other non-standard language. On this type of data, character-level models outperform the subword-based T5 model. Charformer performs on par or outperforms other character-level methods.
The effectiveness of character-level models on multilingual data is evaluated on standard cross-lingual question answering and classification tasks. In this set-up, the Charformer model, as well as the T5 character-based model, are pre-trained on multilingual mC4 Common Crawl data in 101 languages. They are compared with multilingual BERT and multilingual T5 models. The results show that Charformer outperforms the character-based T5 model, and it is competitive with the subword-based baselines and outperforms them in some tasks.
In summary
We have reviewed the Charformer model, proposed by Tay et al. (2022), a re-scaled Transformer architecture that integrates gradient-based subword tokenization. This method allows the model to efficiently learn a latent subword segmentation mixture end-to-end, directly from characters. English and multilingual variants of the Charformer model outperform strong character-level baselines across several tasks, while being more efficient. Furthermore, the Charformer model achieves performance on par with subword-based models on standard English tasks and outperforms them on noisy user-generated data. On multilingual data, the Charformer model performs on par with subword-based models overall, while being faster than both character-level and subword-level baselines.
Dr. Patrik Lambert
All from Dr. Patrik LambertRelated Articles
