Issue #174 - Are Pre-trained Convolutions Better than Pre-trained Transformers?


Introduction and Background
Modern machine learning approaches for natural language processing (NLP) often make use of models that have been pre-trained on general language tasks such as language modeling. These models, such as BERT and GPT-2, are almost always based on the Transformer architecture that employs self-attention to model the relationships between words in a sequence. However, this trend in NLP often conflates the two aspects of (1) neural architecture choice and (2) large-scale pre-training when considering state of the art performance. This has resulted in very little work investigating how well non-Transformer architectures, such as convolutional neural networks, perform when pre-trained in a similar way on large amounts of data.
In this post, we look at the paper “Are Pre-trained Convolutions Better Than Pre-trained Transformers?” by Tay et al, (2021), where they seek to better understand tradeoffs between neural architectures and pre-training regimes by investigating the effect of large-scale pre-training of convolutional NLP models. Additionally, the authors compare performance between Transformer and convolutional models trained directly on classification tasks without pre-training.
In detail the authors present the following research questions:
- Do convolutions benefit from pre-training as much as Transformers, and are they competitive with Transformers?
- What are the tradeoffs between using convolutions versus Transformers (downstream task performance, training time, etc.)
- What are the failure modes and situations where it is best not to use convolutions?
Methods and Approach
Convolutions vs. Self-Attention for NLP
While convolutions are perhaps best known for their applications in computer vision, the authors investigate three convolutional variants and apply them to several NLP tasks. But before we discuss these particular convolutional models, it’s worth taking a bit of time to understand the differences between convolutions and self-attention mechanisms normally used in pre-trained Transformer models such as BERT.
The most important difference between convolutions and self-attention is related to what is called their “receptive fields” or the amount of data each method can process at one time. A limitation of convolutions is that they are only able to process a limited number of tokens at the same time, which restricts the amount of context that can be incorporated when computing word representations. This context size is often referred to as a “filter” hyperparameter, and a depiction is shown in Figure 1 (left) of a convolution operation with a filter size of 3. As shown in the figure, each word representation (depicted as a blue circle) only takes into account the word preceding it, and the word that comes directly after it when modeling sequences. This context can be increased by increasing the filter hyperparameter, but also increases the amount of computations that need to be done and increases training and inference time.
Compare this now to self-attention, which requires no setting of a filter size hyperparameter and can compute word representations that consider the entire context of a sequence. As seen in Figure 1 (right), self-attention uses all pairwise comparisons when computing a representation for a given word within a sequence. This amounts to (theoretically) being able to utilize unlimited context when modeling input sequences, which seems to overcome a major drawback of convolution operations.
 However, this ability to model long-range contexts comes at a significant computational cost. If we denote the number of words in a sentence as n, then self-attention requires n2 operations to model this unlimited context. This computation is also required for each layer in the model, and when we consider how deep self-attention-based Transformers are, this results in a lot of computation and training time, especially compared to convolutional models. Given this dilemma, the authors investigate whether recent advancements in convolutional models can overcome these computational costs while taking advantage of massive pre-training that has benefited self-attention models like BERT.
However, this ability to model long-range contexts comes at a significant computational cost. If we denote the number of words in a sentence as n, then self-attention requires n2 operations to model this unlimited context. This computation is also required for each layer in the model, and when we consider how deep self-attention-based Transformers are, this results in a lot of computation and training time, especially compared to convolutional models. Given this dilemma, the authors investigate whether recent advancements in convolutional models can overcome these computational costs while taking advantage of massive pre-training that has benefited self-attention models like BERT.
Convolution Variants
Now that we have a better understanding of the differences between convolutions and self-attention, we can discuss the convolutional variants the authors employ in their paper. The first of these are called dilated convolutions, which aim to increase the number of input tokens that models can process at once. These convolutions introduce “gaps” in the filters where no weights are stored, enabling these models to process larger context lengths without needing to store as many weights. Figure 2 below gives a depiction of (a) standard convolutions which process a 3x3 receptive field, (b) dilated convolutions with a dilation size of 2 which increases the overall receptive field to a size of 7x7 and (c) dilated convolutions with dilation size of 4, which increases the receptive field to a size of 17x17. In these examples, a “receptive field” refers to how many pixels of an image can be processed by a neural network at once, however this applies to sequence lengths in natural language processing as well.
 Separable convolutions, on the other hand, attempt to make traditional convolution more efficient by splitting a single convolution into smaller sub-operations that can be run in parallel. These convolutions actually result in fewer multiplications while computing the same hidden representations as their standard counterparts. A related variant, called lightweight convolutions, utilizes the advantages of separable convolutions while also reusing weights from the convolutional filters to reduce the number of overall weights required by the model, and the authors utilize this lightweight variant in their experiments.
Separable convolutions, on the other hand, attempt to make traditional convolution more efficient by splitting a single convolution into smaller sub-operations that can be run in parallel. These convolutions actually result in fewer multiplications while computing the same hidden representations as their standard counterparts. A related variant, called lightweight convolutions, utilizes the advantages of separable convolutions while also reusing weights from the convolutional filters to reduce the number of overall weights required by the model, and the authors utilize this lightweight variant in their experiments.
Finally, dynamic convolutions are the most recent variants specifically developed for NLP applications by Wu et al., 2019. These convolutions build upon lightweight convolutions while also learning a position-specific kernel for each timestep in a sequence of words. This is similar to the position embeddings utilized in many Transformer models, but does not require the full pairwise computations required at each timestep that is utilized by self-attention. A depiction of the differences between self-attention and dynamic convolutions is given in Figure 3 below.
 Experimental Setup
Experimental Setup
To test the effectiveness of these convolutional models, the authors focus on fine-tuning models for the following tasks:
- Toxicity Detection: binary classification to determine if text is toxic
- Sentiment Analysis: binary classification of whether text is positive or negative
- News Classification: categorize text into one of four news categories
- Question Classification: determine question category of span of text
- Semantic Parsing: given a span of text, produce a structured semantic representation
For all experiments, the authors use a sequence-to-sequence model based on the T5 architecture for Transformer models. All convolutional models have 12 encoder and decoder layers. For the dynamic and separable convolutional models, all models are trained with a filter size of 7, while the dilated convolutional models are trained with filter sizes ranging from 7 to 31 depending on the layer.
All models are pre-trained on the C4 corpus using a span-based seq2seq objective function. This objective function masks out spans of words during training, and the model is trained to fill in the missing words. For fine-tuning, all models follow the training and inference regime where prompts are prepended to the input text that cues the model for the downstream task (e.g. “identify sentiment: The movie was terrible!”). The model is then trained to generate the appropriate classification in words instead of outputting a single integer label. An example of the inputs and outputs from the model is given in Figure 4 below.
 Results
Results
The authors report either accuracy or F1-score in their results depending on the dataset. Additionally, the authors present separate results for models that are pre-trained on the C4 corpus, and models trained directly on each classification task with no pre-training. Finally, the authors specifically highlight the difference in performance between pre-trained and randomly initialized models across all datasets and tasks. Results are summarized in Table 1 below.
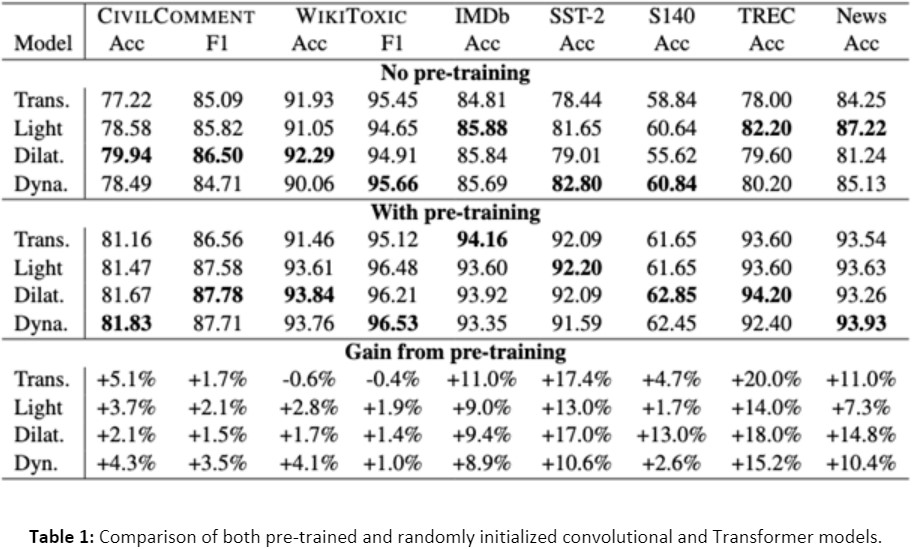 Focusing on the first set of rows, we see that without any pre-training, convolutional models outperform Transformers on all datasets. This seems to present compelling evidence that the architecture alone of Transformer models does not solely account for the state-of-the-art performance across so many NLP tasks. The second set of rows shows results after using the pre-training regime described above for all models. Here we see Transformers outperform convolutions in one case (IMDB sentiment classification), but convolutions are competitive or slightly surpass Transformer performance on all other datasets. This suggests that large-scale pre-training is beneficial to different types of neural architectures outside Transformers and could open up further research into exploring pre-training for these other neural models.
Focusing on the first set of rows, we see that without any pre-training, convolutional models outperform Transformers on all datasets. This seems to present compelling evidence that the architecture alone of Transformer models does not solely account for the state-of-the-art performance across so many NLP tasks. The second set of rows shows results after using the pre-training regime described above for all models. Here we see Transformers outperform convolutions in one case (IMDB sentiment classification), but convolutions are competitive or slightly surpass Transformer performance on all other datasets. This suggests that large-scale pre-training is beneficial to different types of neural architectures outside Transformers and could open up further research into exploring pre-training for these other neural models.
While these results answer the research questions about task performance, they do not shed light on practical questions of training time. To understand this, the authors investigate how increasing the input sequence length impacts training speed for both Transformers and convolutional models (see Figure 5 below). We can see in this figure that Transformers are competitive with convolutions up to approximately 512 input tokens, after which convolutions demonstrate a fairly pronounced increase in processing speed. This suggests that in addition to performing as well as Transformers on classification tasks, convolutions are faster as they process longer inputs and perhaps more efficient in the number of floating point operations.
 Finally, the authors also briefly highlight cases where convolutional models fall short of Transformers and note that tasks that require modeling pairs of sentences, such as natural language inference or question answering, benefit greatly from Transformers. In particular, on the MultiNLI dataset, the authors report an accuracy of 75% from convolutional models, while Transformer models easily beat this score at 84% accuracy. While this highlights a limitation of convolutions in certain settings, it is somewhat expected given that Transformers are able to attend to both text segments within a pair of input texts, while convolutions struggle to do this with their more limited context.
Finally, the authors also briefly highlight cases where convolutional models fall short of Transformers and note that tasks that require modeling pairs of sentences, such as natural language inference or question answering, benefit greatly from Transformers. In particular, on the MultiNLI dataset, the authors report an accuracy of 75% from convolutional models, while Transformer models easily beat this score at 84% accuracy. While this highlights a limitation of convolutions in certain settings, it is somewhat expected given that Transformers are able to attend to both text segments within a pair of input texts, while convolutions struggle to do this with their more limited context.
In summary
In their paper, Tay et al., (2021) present interesting experiments that show how different convolutional models can be competitive with, or slightly outperform, Transformer models. They also show that large-scale unsupervised pre-training is beneficial to convolutional as well as Transformer models, suggesting that there needs to be a more careful distinction between the contribution between neural architecture design and pre-training regimes. Finally, the authors also demonstrate how convolutions can be more efficient during training when processing very long sequences, but may have drawbacks in some modeling scenarios when self-attention may be needed. This paper presents many new opportunities to study the impacts of pre-training with other neural models outside Transformers to better understand which models benefit from the pre-train and fine-tune training regime that has become so widespread throughout the NLP community.