
Data annotation and labelling
Our AI data specialists deliver the highest quality of data annotation and data labelling services to rapidly train and fine-tune your AI models.

The challenge
Data does not always equal knowledge – the data used to train your AI model must often be annotated or labelled so that your model can effectively learn from it. To do this, you need the right data annotation and labelling tools, as well as a diverse group of people with the right skillset to accurately annotate and label your data. But securing the tools and sourcing the required talent can be challenging and costly. RWS has the tools and expertise you need.


The solution
TrainAI from RWS provides comprehensive data annotation and data labelling services by leveraging our TrainAI community of active, vetted, skilled, and qualified AI data specialists. Whether you need responses rated, audio transcribed, speakers identified, images segmented, or objects tracked, our labelled datasets enable you to train your AI model to the highest standards.
TrainAI is technology agnostic – we’ll work with the data annotation tool of your choice, whether it be your own proprietary technology, the TrainAI platform, or a third-party solution.
Today, TrainAI-annotated data is used to train the world’s largest generative AI, large language models (LLMs), and other AI applications.
TrainAI data annotation and labelling services

Categorization and classification
We categorize and classify data to provide a structured framework from which AI models can learn including:
- Text categorization such as classifying customer reviews and social media posts to aid in sentiment analysis
- Image classification to enable facial recognition systems to recognize and identify distinct facial features
- Audio classification by speaker or language to train voice recognition systems to respond to various voice commands
- Video classification into categories such as sports or documentaries to improve recommendation systems
- And more
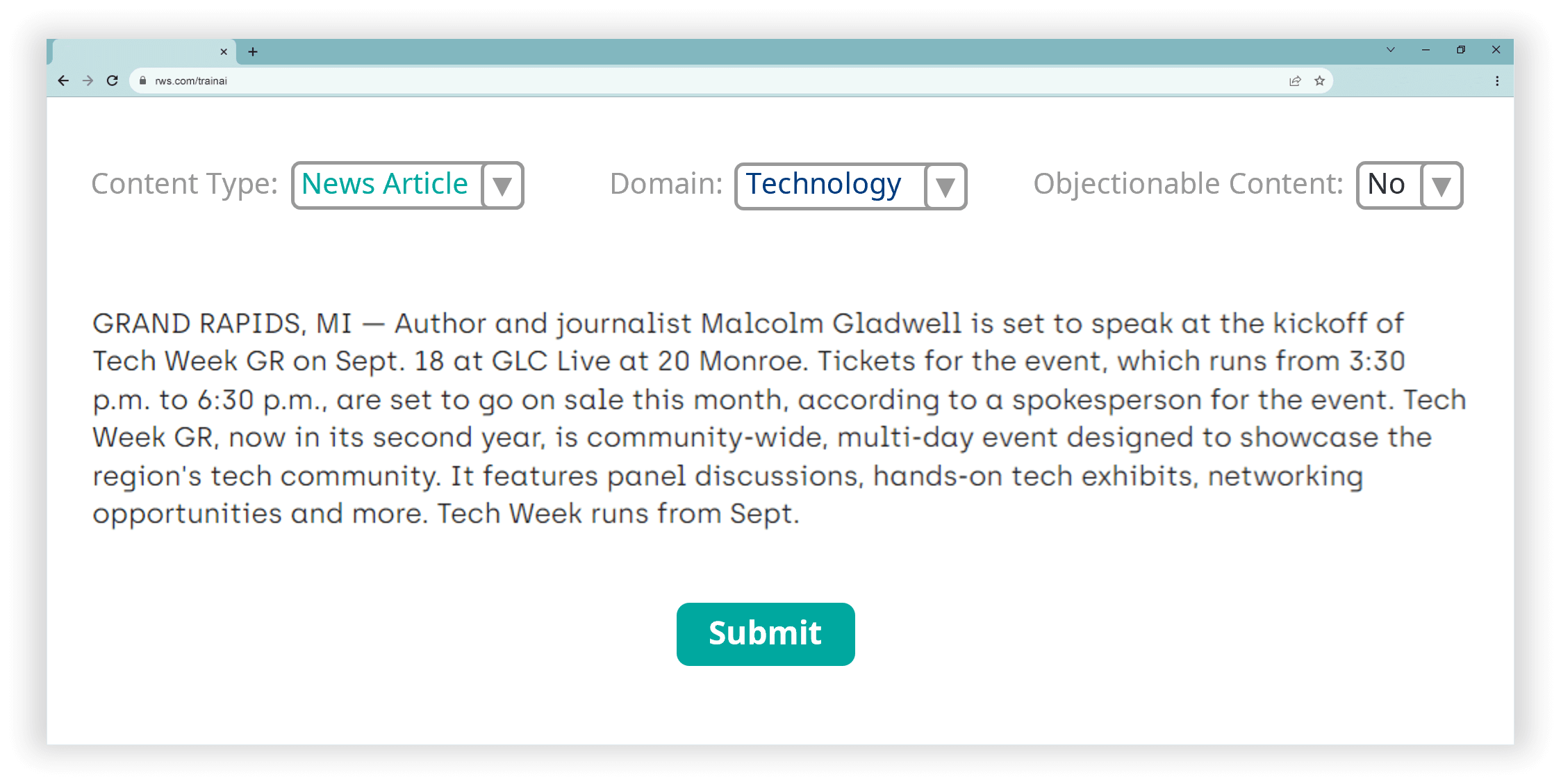
Transcription
We convert audio and speech data into written text, and subtitle and caption video data, to provide structured information from which AI models such as voice recognition and natural language processing (NLP) applications can analyze and learn.
Named entity recognition
By identifying and categorizing named entities such as person names, organizations, locations, time expressions, quantities, and other pertinent entity types in text, we enable AI models to accurately interpret and extract valuable information from unstructured text data. With TrainAI’s named entity recognition (NER) annotation services, chatbots can personalise responses, geo-targeting applications can provide location-specific services, and event-planning apps can correctly schedule events.
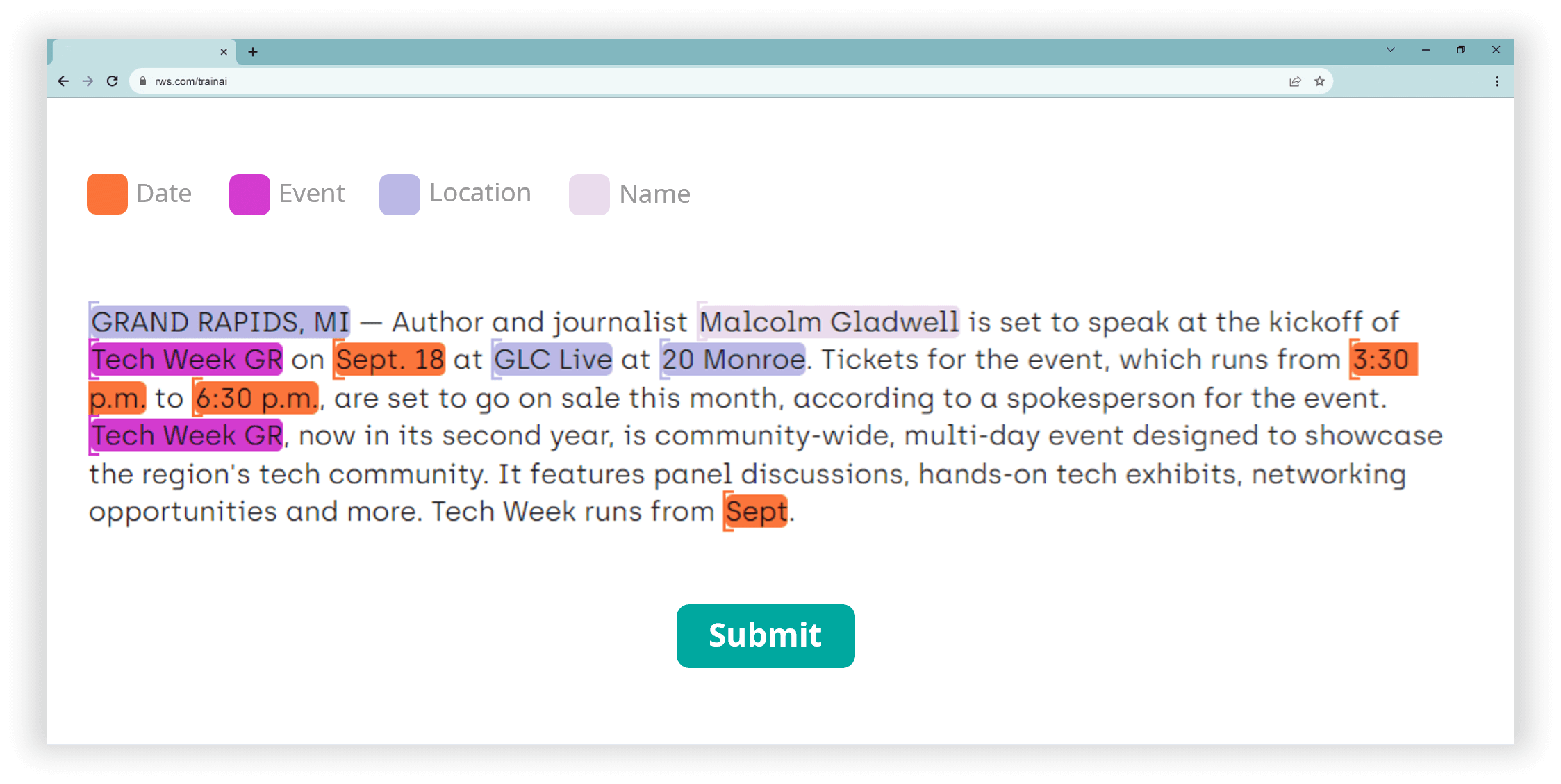

Feature and object annotation
We meticulously annotate features or objects of interest to help train AI models to recognise them by providing video and image annotation services:
- Landmark annotation: Labelling specific key points or landmarks in an image e.g., for facial recognition systems
- Attribute annotation: Labelling specific object characteristics in a dataset to power search and recommendation systems
- Bounding box annotation: Drawing boxes around objects in images or video frames for object detection / recognition AI
- Polygon annotation: For more complex shapes, plotting points along an object's boundary to form a polygon
- Semantic segmentation: Labelling every pixel in an image to the object to which it belongs, providing the detail required e.g., for self-driving technologies to understand road scenes
- And more
Sentiment analysis
To help AI models learn to understand the nuances of human emotion and opinion, we perform sentiment analysis or opinion mining by analyzing the emotional tone or sentiment expressed in text, classifying it as positive, negative, or neutral, and scoring it on sentiment intensity.

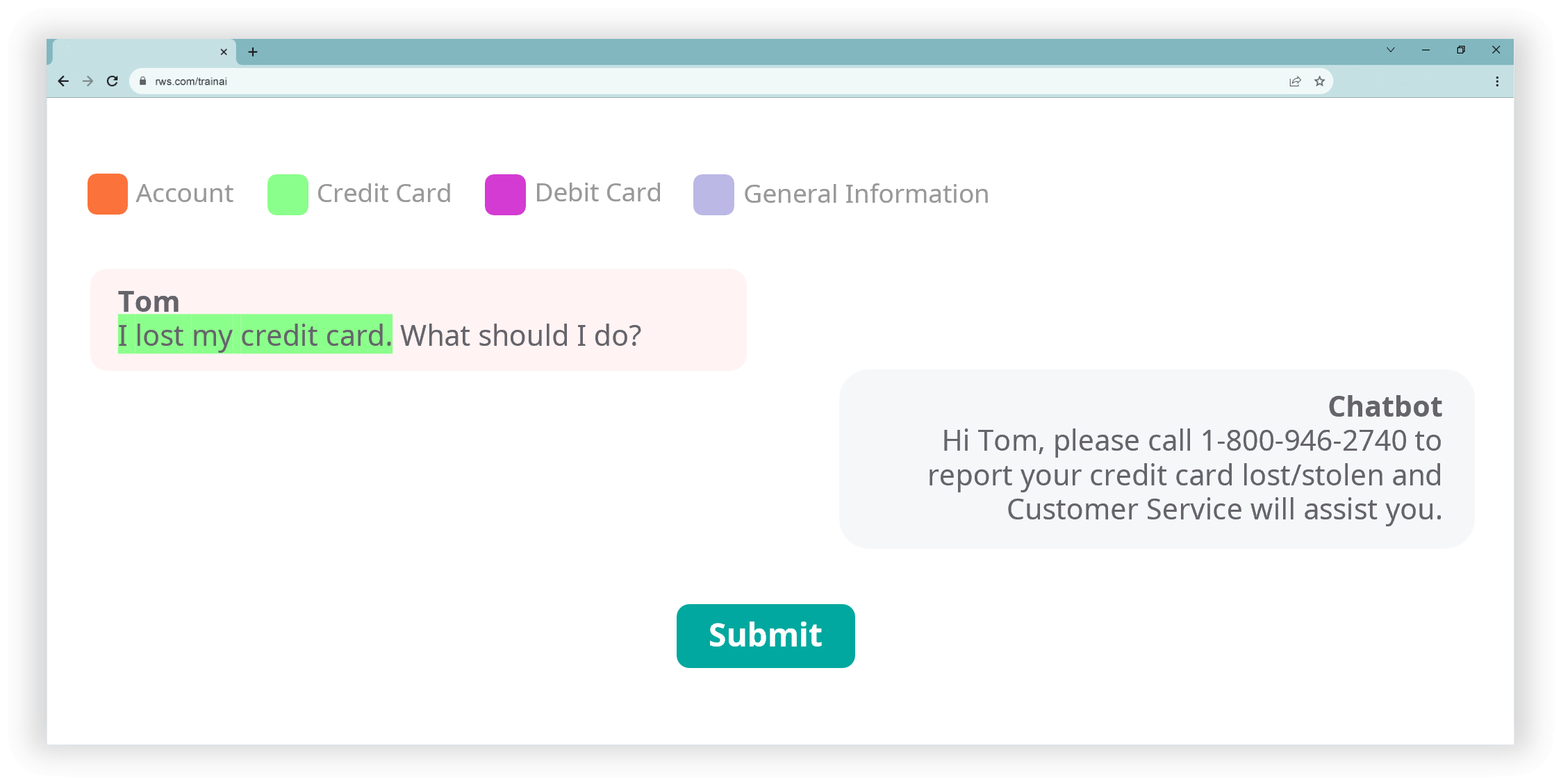
Intent annotation
We provide intent annotation by labelling or categorizing text to determine the underlying intent or purpose of the communication, helping AI applications like chatbots and virtual assistants understand what action or information a user wants.



Types of AI data delivered by TrainAI
Text data
Audio / speech data
Image data
Video data
Locale-specific data
Synthetic data
Our TrainAI community
Instead of crowdsourcing your data needs to anyone and hoping for the best, we deliver AI training data collected, annotated, and validated by our TrainAI community of active, vetted, skilled, and qualified AI data specialists based on your specific ML project requirements.

community members
language variants

countries
Train AI Resources








Let's connect
Connect with our TrainAI team to discuss your AI training data needs or submit a TrainAI community support request.
Contact us
Want TrainAI to prepare data to train or fine-tune your AI models? Complete the form below.
Community-related inquiries submitted via this form will not receive a response. For community-related inquiries, submit your request here.
Loading...